Rule Based Annotations
| 🚧 This page is not published on techdocs.gbif.org. It is only visible on the test and development sites (this is techdocs.gbif-test.org). 🚧 |
| This is an experimental feature, and the implementation may change throughout 2024. The feature is currently available for preview on the GBIF test environment, GBIF-Test.org. |
This project is part of the indicative tasks for 2023 GBIF work programme.
Explore approaches to annotation capabilities in GBIF.org that enable data corrections, enrichments and user-provided rules that combine taxonomic, geographic and temporal combinations to detect suspicious records.
Summary
Rule based annotations is an experimental tool being developed within GBIF that will allow users to mark certain occurrence data searches with a controlled vocabulary of helpful terms. Currently, the project is focused on annotating geographic locations, but this likely expand in the future. Although many features have been developed, this project should be considered a work in progress and experimental. The main goal of the project is to facilitate occurrence data cleaning and user feedback.
Road Map
Initiated tasks with ✓.
User Interface ✓
A demo UI has been developed to facilitate the process of creating rule-based annotations on a map. This user-friendly interface allows users to visually interact with a map and define rules or criteria for data annotations.
The current state of the demo UI for rule-based annotations is considered a work in progress, and it is expected to evolve based on valuable feedback gathered during the pilot user testing phase.
API backend ✓
The main underlying technology that will be power the annotations will be a database store and a restful API interface.
R package gbifan ✓
Initially the main way to interact with the annotations store, will be through the API or R.
The R package can be found here.
Seeding rulesets ✓
Seeding rulesets into our annotation store provides several benefits, especially when it comes to improving user experience. Seeding data can help new users get acquainted with the annotation system more quickly. By providing sample data or pre-existing annotations, users can learn how the system works and what is expected of them in terms of annotation tasks. This can reduce the learning curve and increase user engagement. New and pilot Users can be more productive when they have access to seeded data. They can start their annotation tasks immediately instead of filling in well-known information.
| World Checklist of Vascular Plants |
|---|
Introduction to internal and external pilot users ✓
Before releasing the rule based annotations tool to the public, it will undergo internal and external piloting phase. In this phase, pilot users will be given a small annotations task within a group they are familiar. The pilot users will then be interviewed about their overall experience, particularly if there were any "rules" or annotations they wanted but make but could not.
Data paper
After the internal and external review we plan to write a data paper that will present the annotations tool to wider audience. The internal and external pilot users will be encouraged to be co-authors on the paper. The "data" part of the data paper will be an export of rules that were created during the pilot phase.
User Guide
If you are reading this you have been approached as potential pilot annotator, and you have probably been asked to complete a small but useful annotation task that is useful for you. This guide is meant to as an aid to get you started.
Using the UI
If you are a pilot user, you should already have your project ruleset permissions set up for you.
How to make rules
To make a rule
-
Log in with your GBIF username and password.
-
Select the project and ruleset you want to make a rule in. Alternatively, you can leave these blank if you want to make a one-off rule.
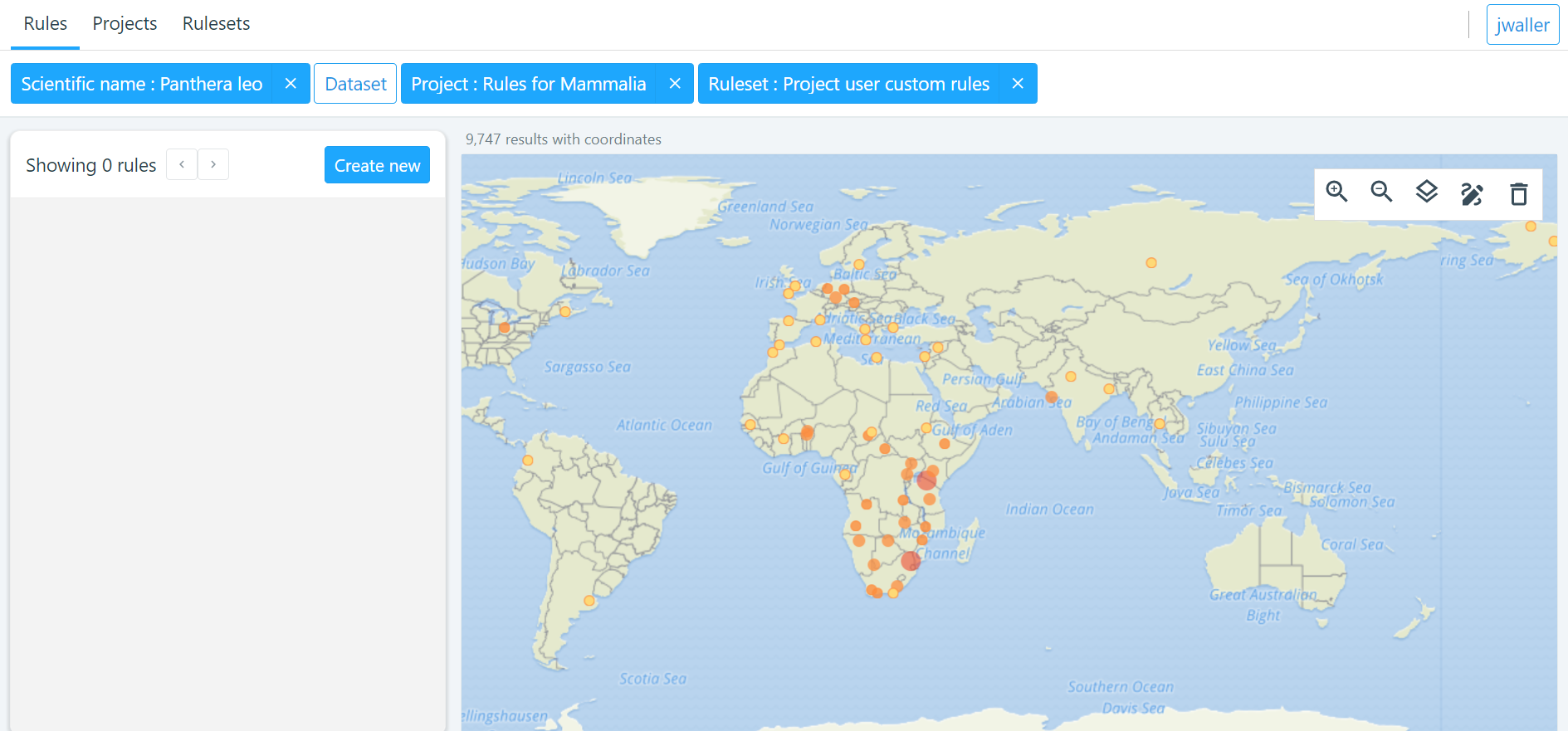
-
draw a polygon or select region you want to make the rule about.
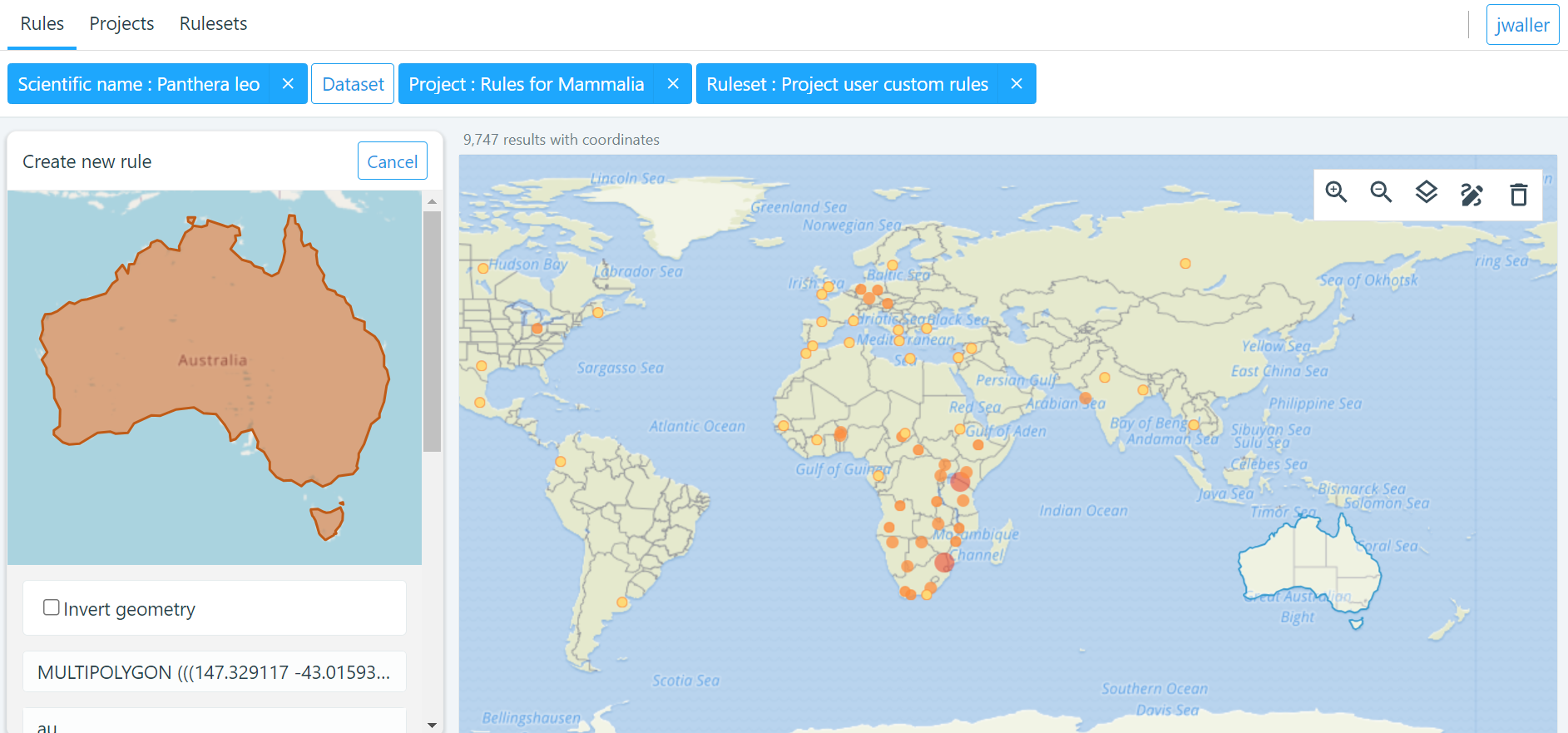
-
Next apply your label.
| term | definition |
|---|---|
Native |
Refers to the natural geographic range where a species or organism historically evolved and occurs without human intervention. |
Introduced |
Refers to the geographic area where non-native organisms have been intentionally or accidentally introduced and established |
Managed |
Encompasses the geographic area where specific species are actively controlled, conserved, or manipulated by human intervention. |
Former |
Denotes the historical geographic area where a species once naturally occurred but no longer does due to various factors. |
Vagrant |
Describes sporadic occurrences of a species far outside its usual habitat or distribution, often due to rare or accidental dispersal events. |
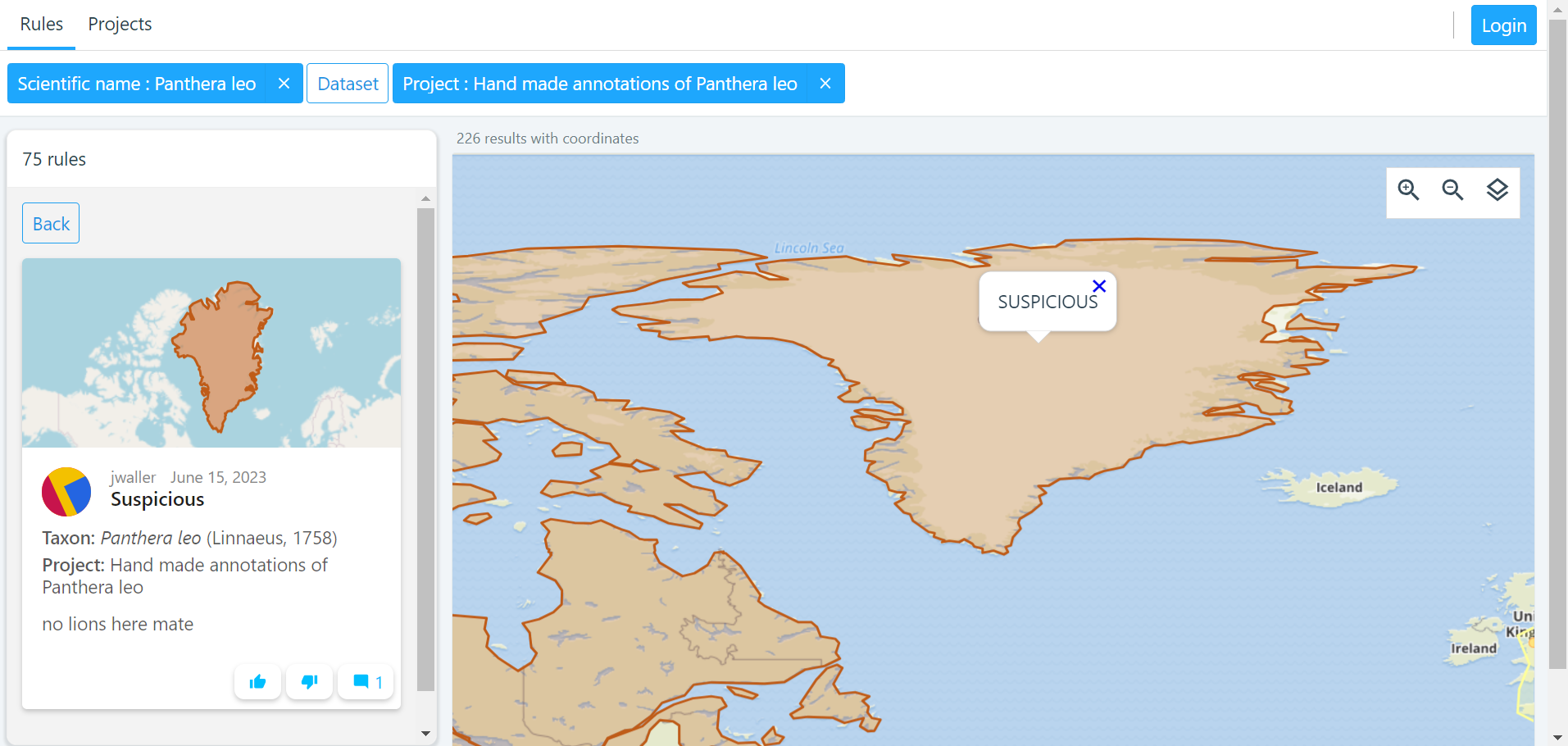
Suspicious |
Occurrences occurring in the designated area might be in error in some way. |
If vocabulary this doesn’t work for you, please pick the closest fitting, and request additional vocabulary in your feedback.
Create your rule.
Good rules
While there is not absolute definition of a good rule and a bad one.
Good annotations usually have a few properties:
-
Good annotations usually don’t use extremely complex polygons. If you find yourself needing to trace the coastline of Italy, you might be doing too much work. A good annotation should take into account a little bit of buffer to take into account occurrence record uncertainty. Many GBIF mediated occurrences do not have the resolution to justify making highly complex polygons. Also it’s difficult for us to store very large polygons.
-
Good annotations take into account future occurrence records. Remember that your annotations should be able to fit future occurrence fairly well.
-
Good annotations also try to think about higher taxonomy and simplification.
Introduction
Data cleaning
The Global Biodiversity Information Facility (GBIF) is a vital data infrastructure for researchers, conservationists, and policymakers across the globe. It aggregates and mediates access to extensive datasets of biodiversity occurrence records, thereby fostering scientific research, conservation efforts, and informed decision-making. Nevertheless, the quality of these records is pivotal for their "fitness for use", and data cleaning becomes an essential process to ensure their reliability and utility.
As the volume and complexity of occurrence data continue to grow, the need for automated data cleaning tools has become more important. R packages like https://docs.ropensci.org/CoordinateCleaner/[CoordinateCleaner] (2018) have played a key role in addressing this need, providing efficient and user-friendly solutions for common data quality issues.
Fixing at source
A competing viewpoint with regard to data cleaning is to "fix at source". Fixing GBIF occurrence data at the source, such as reaching out to data publishers to address issues and errors in their datasets, is an ideal approach in theory. However, in practice, this approach often encounters challenges, primarily because publishers may not respond to emails or communication attempts. It’s essential to bear in mind that rule-based annotations can contribute to rectifying data problems at their origin as well. Additionally, it is often the case that records do not need to be fixed, but merely are not acceptable for a certain application, such as species distribution mapping.
Motivation
Automated solutions, like CoordinateCleaner, while valuable tools for data cleaning, may be considered incomplete in certain contexts due to their limited flexibility and potential to miss edge cases. A rule-based annotation system, on the other hand, allows users to make data quality decisions that fit their use case in a more granular way.
Complexity vs usability
Annotation systems, like any software or tool, have the potential to become unusable when they become overly complicated.
One goal of a our rule-based annotation system is to make it accessible to a broad user base, including researchers, scientists, and casual users. If the system becomes overly complex, it can discourage potential users who may not have a deep technical background or a lot of time, but still have valuable feedback.
A rule-based annotation system, especially one used for annotating complex datasets like GBIF occurrence records, must strike a delicate balance between complexity and usability.
Controlled vocabulary
One of the key ways to increase usability and complexity is to introduce a controlled vocabulary.
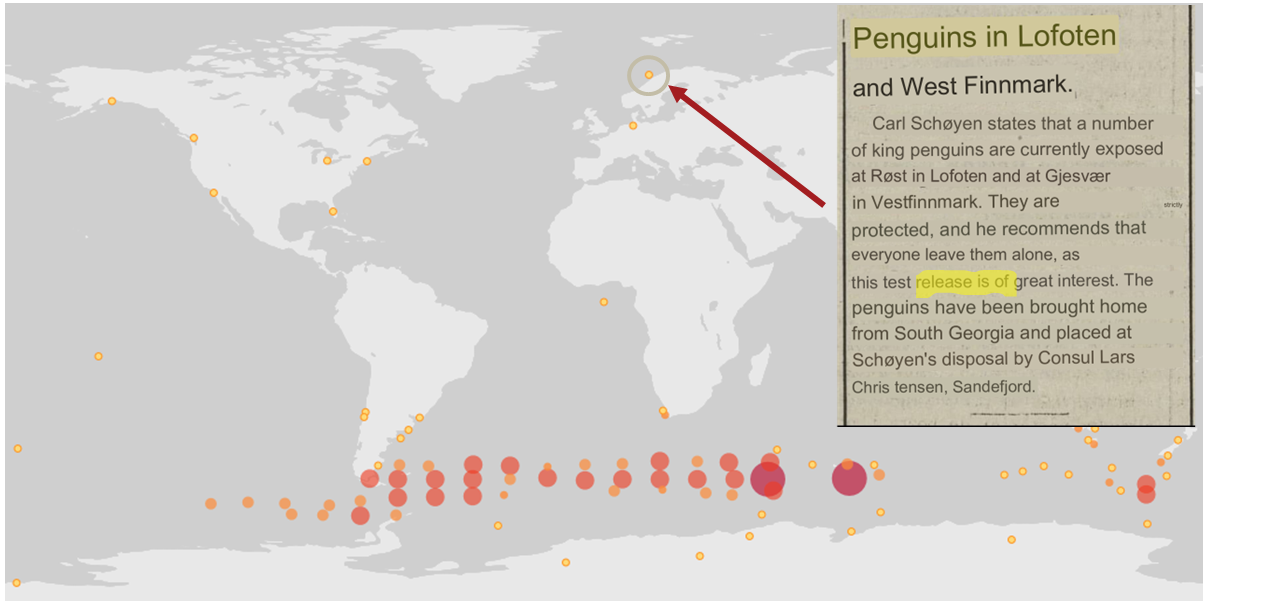
Using a small controlled vocabulary over in an annotation system offers several advantages to downstream users. Finding the right level of granularity and flexibility within the controlled vocabulary is key to reaping the benefits while accommodating the specific needs of the annotation user.
Technical Details
Rules
A basic rule in our system looks like this.
rule → taxon in geo-polygon are controlled vocab
In our system a geo-polygon is a Well-Known Text (WKT) object. A geo-polygon could also be the name of a place that eventually maps to a WKT polygon (like a country code or GADM code).
|
|
|
|
A taxon in our system is going to be a GBIF taxonKey so rules are more likely to look like this in practice.
|
|
|
|
Rulesets
A ruleset is a collection of rules.
For example, a ruleset could be "Annotations of the Genus Leo", and it could look something like the table below.
|
|
|
|
|
|
Projects
A project is a collection of rulesets.
Projects are designed to allow for collaboration between users and logical grouping of rulesets. For example, a ruleset could focus on Lions, but be part of a bigger project about cleaning up Mammal occurrence records.
|
Annotations of Lions based on Field Guide |
|
Annotations of Mammals that are not in the Ocean |
|
Suspicious Zoo Locations of North America |
|
Adapted iNaturalist atlases of Mammals |
|
Suspicious Centroid locations for Museum Specimens |
Note how a project can encode knowledge from other sources into a ruleset, such as iNaturalist atlases.
Collaboration
We hope that users will collaborate on a project that interests them and create rulesets that are widely beneficial to others within their research community.
Within a project, only users with access, granted by the project creator, will be able to create rules and rulesets. However, rules, rulesets, and projects will all be open and publicly available.
Voting
For downstream users, deciding which rule and rulesets to use might become challenging without some quality control. Currently, we imagine a simple upvote-downvote system on rule, ruleset, and perhaps project. With voting users could see what annotations are supported by the broader community, and create cleaning scripts that are only use annotations supported by the community.
Additionally, voting could provide protection against vandalism.
Higher taxonomy
Annotating higher taxonomy is harder than annotating at the species level because you have to be confident, the annotation at the higher level fits all child taxa.

Given the distribution of Amphibians, a good rule for the high taxon Amphibians would be :
rule → Amphibians in Antarctica are Suspicious
One challenge is that is is hard to downcast annotations like "Native" to lower levels, since species of a big group tend not to be "Native" to exactly the same areas.
Conflicting rules
Inevitably, there are going to be rules created in our system that conflict. For example, a user might mark and area as "Native", while another user will mark the same area as "Suspicious".
In our rule-based system, unlike perhaps other platforms, we are not striving to create a single ground truth. We aim only to have a collection of useful opinions, and we leave it to the end user to decide what to do with the information.
Controlled vocabulary
We might consider using the preexisting vocabulary, although we are attempting to annotate land area (ranges) more than we are attempting annotate occurrence records.
Below is the working controlled vocabulary for location-based annotations.
| term | definition |
|---|---|
Native |
Refers to the natural geographic range where a species or organism historically evolved and occurs without human intervention. |
Introduced |
Refers to the geographic area where non-native organisms have been intentionally or accidentally introduced and established |
Managed |
Encompasses the geographic area where specific species are actively controlled, conserved, or manipulated by human intervention. |
former |
Denotes the historical geographic area where a species once naturally occurred but no longer does due to various factors. |
Vagrant |
Describes sporadic occurrences of a species far outside its usual habitat or distribution, often due to rare or accidental dispersal events. |
Suspicious |
Occurrences occuring in the designated area might be in error in some way. |
This vocabulary is meant to be a compromise between modeling species ranges and establishment means accurately, while not being overly complex.
| concept | example |
|---|---|
native |
extant |
native |
endemic |
native |
indigenous |
native |
breeding |
native |
non-breeding |
introduced |
assisted colonization |
introduced |
invasive |
introduced |
non native range |
managed |
location is captive range |
managed |
location is botanical garden |
managed |
location is zoo |
managed |
cultivated in glasshouse |
suspicious |
location is in the ocean |
suspicious |
zero-zero coordinate |
suspicious |
centroid |
suspicious |
area too far north for taxon |
suspicious |
area too high elevation for taxon |
suspicious |
area is natural history museum |
former |
fossil range |
former |
extinct |
former |
historic |
vagrant |
migrant |
The current vocabulary might change in the future. Namely, there has been some discussion introducing hierarchy such that perhaps certain terms map to present or absent for example.
Why not annotate occurrences directly?
Annotating land areas (and extensions) provide at least two advantages over annotating occurrences:
-
Avoids the use of unstable gbifIds.
-
Allows for future occurrences to benefit from the annotation.